I wanted to explore how far I could push Bolt. New to generate usable mobile prototypes by feeding it a powerful prompt, either from a reference image or text alone.
This time, I had a focused experiment in mind: Would Bolt generate better results using just a text prompt, or would combining it with a visual reference make a noticeable difference?
I started by finding a UI reference on Dribbble: a clean, minimal mobile layout showing furniture in context, with product tags, filters, and prompts to decorate spaces using AI.
Before jumping into Bolt, I uploaded the reference image to GPT and asked it to write a descriptive prompt optimized for Bolt.new. It returned something surprisingly close to the actual layout — structured content, category filters, AI call-to-actions, and a clear visual logic.
Image Prompt
A mobile app for discovering and shopping home furniture. Includes a discovery feed with product cards, filters by category (e.g. Table, Chair, Bedroom), and tappable elements. Product pages show images, materials, and prices. Features AI-powered tools like “Decorate with prompt” and “Decorate your room” with text inputs and tags (e.g. room size, style). Bottom navigation with Home, Explore, Bag, and Profile. Clean layout with modern UI and rounded elements.
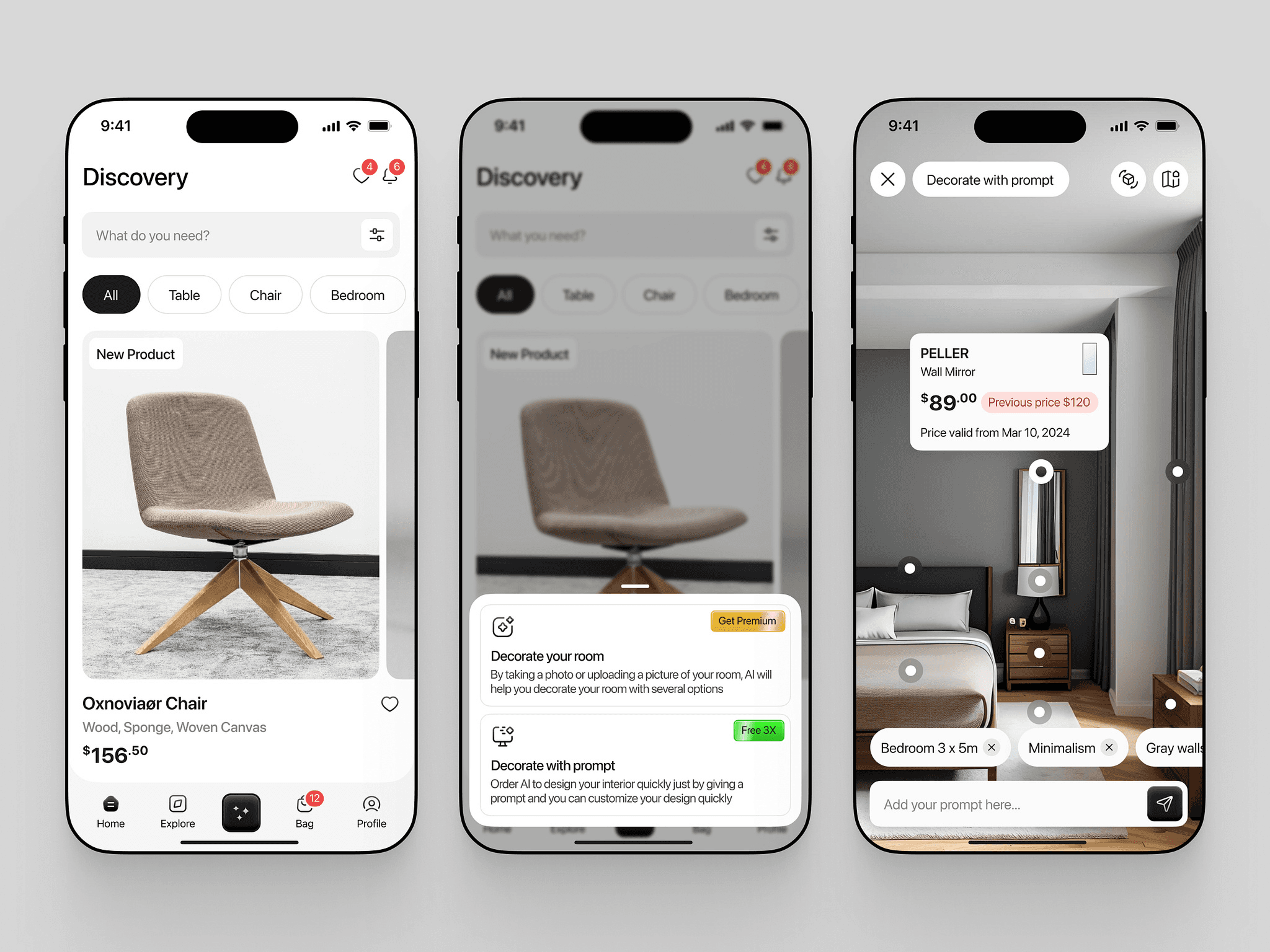
Image reference by @YasserKhalil on Dribbble.
I pasted this into Bolt and got a solid first version almost instantly. To test the prototype on a real device, Bolt prompted me to download Expo, a companion app that lets you preview the flow live on your phone. Within minutes, I was tapping through a working mockup with transitions and screen changes — no code required.
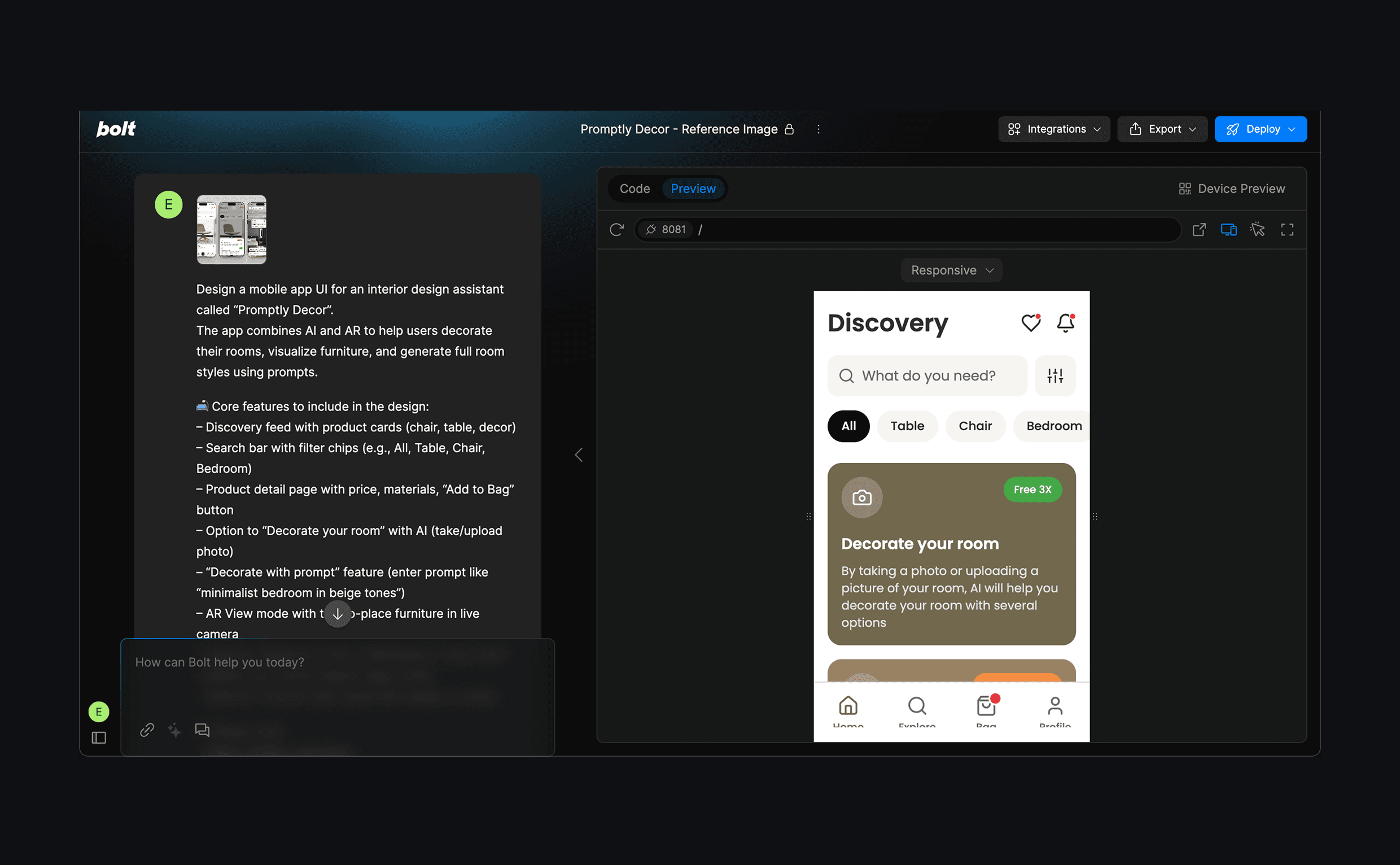
As shown in the video, most CTAs and sections within the prototype were tappable. Bolt didn’t just generate static screens — it created a semi-functional experience where clicking buttons or cards revealed more UI states and information than I had explicitly designed.
Of course, this was still just a prototype. I didn’t connect any back-end logic (even though Bolt supports it), but the interaction fidelity was high enough to share and validate the idea quickly.
After testing Bolt, new with a combined input (text + image), I reran the same experiment, but this time using only the text prompt I had extracted earlier from the image.
To my surprise, the result felt even stronger. The UI Bolt generated was more detailed, with extra touches that made the prototype feel more dynamic. There were more tappable actions, better spacing, and the flow between screens felt more intentional, even though I hadn’t provided any visual reference this time.
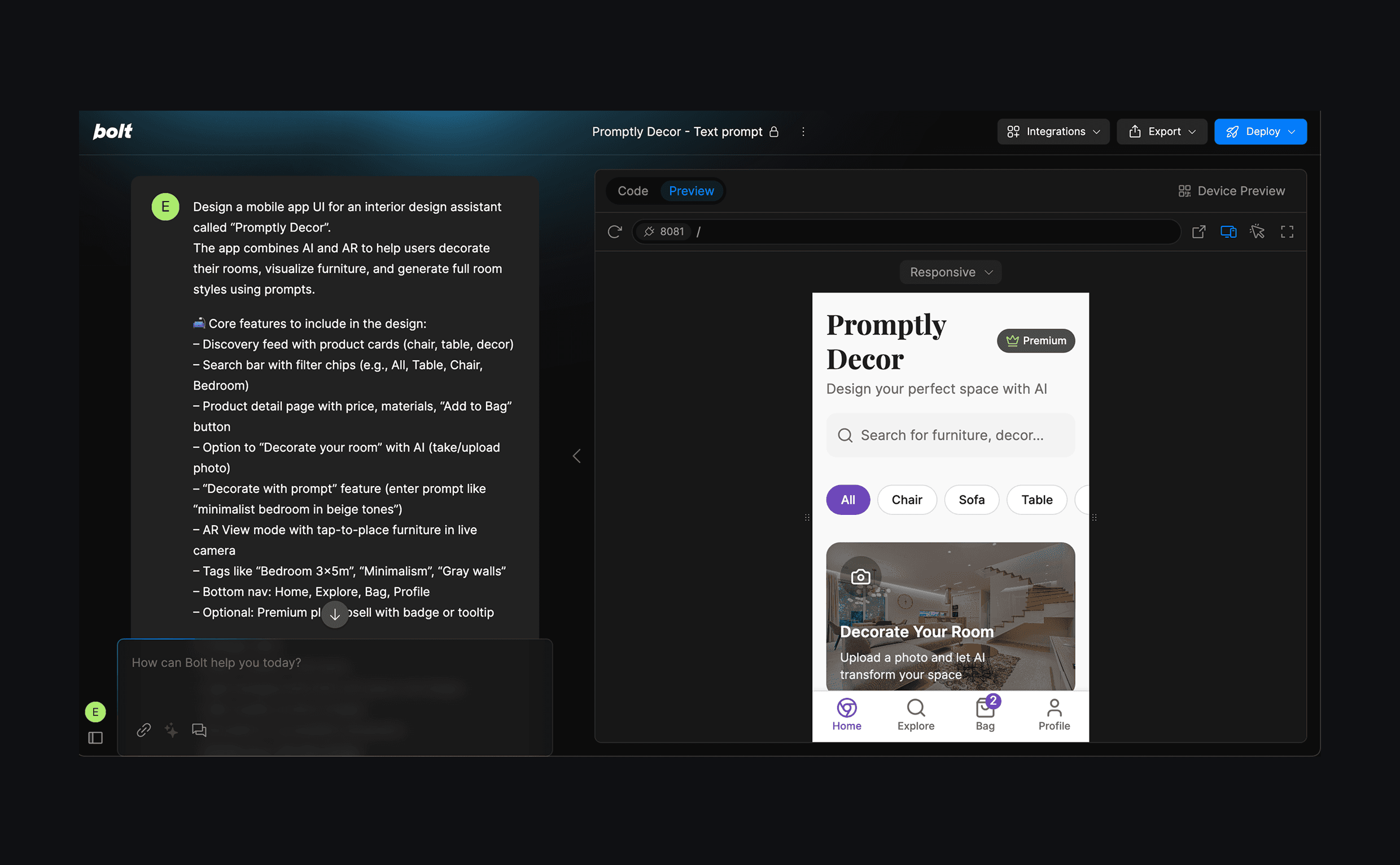
I tapped the “Decorate your room” button and Bolt triggered my phone’s camera — simulating a VR flow. The camera opened, but as soon as I took the photo, the prototype crashed (which honestly made me laugh more than anything else).
Still, it was enough to show how far this type of tool can stretch — even simulating camera or AR flows based only on prompt interpretation.
This experience helped me see that starting with a well-crafted prompt inspired by a visual reference often leads to better results than uploading the image directly. I can’t say exactly how Bolt processes visual inputs, but when I used GPT to extract and refine a prompt from the reference image, the output felt more polished and intentional.
Describing the design in words gave me more control over the result while still staying true to the original vision.
Bolt.new feels like a supercharged playground for early concepting. The speed, fidelity, and ability to simulate flow and structure without touching a design tool makes it a powerful option — especially for ecommerce or mobile UX ideas that rely on layout and product logic.
While it’s not a replacement for deep product design, it’s an impressive way to get from idea to interaction fast.